NLP Series - Linguistics

Natural Language Processing Basics - Linguistics
Natural language processing (NLP) is a field at the intersection of computer science, artificial intelligence, and linguistics. NLP is performed by solving a number of sub-problems, where each sub-problem constitutes a level. Note that, a portion of those levels could be applied, not necessarily all of them. Also, the levels could be applied in a different order independent of their granularity.
This article is part of Natural Language Processing series where we cover most prominent building blocks in building Natural Language Processing(NLP) applications. In this article, we shall discuss some of the linguistic concepts that help in understanding NLP techniques.
Let’s dive in to some of the subfields of linguistics that are vital for understanding NLP systems:
1. Phonetics & Phonology
2. Morphology
3. Syntax
4. Semantics
5. Pragmatics
There are a couple of other topics we should keep in mind when understanding linguistics for the purpose of building NLP systems and understanding them certainly helps in understanding how NLP systems work.
1. Sociolinguistics 2. Computational Linguistics 2. Writing Systems
Phonetics & Phonology
Phonetics is the study of individual sounds in verbal languages, or handshapes in sign languages. It deals with the production of speech sounds by humans, often without prior knowledge of the language being spoken. It also looks at the concept of voicing, occurring at the pair of muscles found in your voice box. For instance, the same sound may be represented by many letters or combination of letters(i.e. All underlined letters have same pronounciation: he, people, key, believe, seize, machine, seas, see, amoeba). The same letter may even represent a variety of sounds.
In 1888, the International Phonetic Alphabet (IPA) was invented in order to have a system in which there was a oneto-one correspondence between each sound in language and each phonetic symbol. The IPA uses symbols to represent a great variety of sounds.
Phonology refers to the study of how the individual sounds or handshapes are combined into specific patterns. It is a branch of linguistics that studies how languages or dialects systematically organize their sounds. The fundamental unit of sound in a language is the Phoneme. Phonemes are specifically important in applications involving speech understanding, such as speech recognition, speech-to-text transcription, and text-to-speech conversion. Languages have phonologies, which are collections of phonemes and rules about how to use and realize the phonemes.
Morphology
Morphology is the study of morphemes. A morpheme is the smallest unit of language that has a meaning. Not all morphemes are words, but all prefixes and suffixes are morphemes. For instance, in the word “multitasking”, “multi-“ is not a word but a prefix that changes the meaning when put together with “task”. “Multi-“ is a morpheme. Lexemes are the structural variations of morphemes related to one another by meaning. Morphological analysis, analyzes the structure of words by studying its morphemes and lexemes, and is a foundational block for many NLP tasks, such as tokenization, stemming, learning word embeddings, and part-of-speech tagging.
There are four kinds of morphemes, defined by unbound versus bound and content versus functional: Content morphemes, Functional morphemes, derivational affixes and inflectional affixes. Content morphemes(Unbound content morphemes or lexical morphemes) express a concrete meaning or content, and function morphemes have more of a grammatical role. For example, the morphemes cat and fast can be considered content morphemes. On the other hand, the unbound functional morphemes are words that perform a function in a sentence. The examples include words like “they” and “will” which are used to make the future tense. Then, there is bound content morphemes(also called derivational affixes), that turn one word into another. For instance,”er” used with word “call” can turn the word into another word “caller”. The last one, Bound functional morphemes or inflectional affixes, refers to the affixes that indicate the function of a word in a sentence. Examples : “-ed” (past tense, “cook” + “-ed” = “cooked”, “-(e)s” (plural, “flower”+”-(e)s” = “flowers”, “pass”+”-(e)s” = “passes”)
Syntax
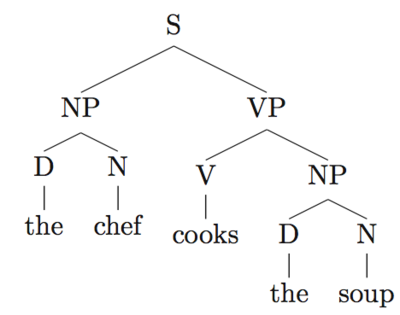
Syntax is a set of rules to construct grammatically correct sentences out of words and phrases in a language. Syntactic structure in linguistics is represented in many different ways. A common approach to representing sentences is a parse tree, also called as phrase structure trees (PSTs). Let’s look at the PST in Figure 2 for the following sentence:
The chef cooks the soup.
Semantics
Semantics, is the study of the meaning of linguistic elements. It is the direct meaning of the words and sentences without external context. One feature of the field of semantics is, modeling how meaning is composed from the structures of language, so semantics is most closely related to syntax. Most projects that use NLP are looking for the meaning in the text being analyzed, so we will be revisiting this field multiple times.
Pragmatics
Pragmatics is a subfield that looks at the use and meaning of language in context. It will help us understand the intent behind the text we are analyzing. It adds world knowledge and external context of the conversation to enable us to infer implied meaning. It is sometimes defined in contrast with linguistic semantics, which can be described as the study of the rule systems that determine the literal meanings of linguistic expressions.
According to Roman Jakobson, we can divide the functions of language into six factors which are required for communication. This model of pragmatics considers messages as focusing on some combination of these factors. Following are the six functions (with the associated factor):
- Emotive (the addresser)
- Conative (the addressee)
- Poetic (the message)
- Metalingual (the code)
- Phatic (the channel)
- Referential (the context)

Sociolinguistics
Sociolinguistics is the study of the complex relationship between language and society. Although sociolinguistics is not a major subfield of linguistics, it is an interdisciplinary field between sociology and linguistics. Understanding the social context of text is important in understanding how to interpret the text.
Every individual has their own unique personal version of language. The collection of varieties that an individual speaks can be considered an idiolect. The different varieties that an individual uses are called registers. Registers covers the concept of formality as well as other manners of speech, gesture, and writing.
Computational Linguistics
Computational linguistics is the scientific and engineering discipline concerned with understanding written and spoken language from a computational perspective, and building artifacts that usefully process and produce language, either in bulk or in a dialogue setting. It is the study of linguistics from a computational perspective. This means using computers and algorithms to perform linguistics tasks such as marking your text as a part of speech (such as noun or verb), instead of performing this task manually.
Writing Systems
In this article we’ve discussed many aspects of language, but so far we’ve focused on aspects that are part of language that is either only spoken or both spoken and written. Writing system, also called as Orthography, refers to the set of conventions used to represent a language in writing.
The smallest meaningful contrastive unit in a writing system is called a grapheme. There are various kinds of writing systems depending upon what the grapheme is used to represent. Alphabets, abjads, abugidas, syllabaries and logographs are some of them. We shall discuss each one of them in detail.
An alphabet is a phonetic-based writing system in which there is a symbol representing consonants and vowels. Examples of alphabet writing systems include Latin, Cyrillic, Greek, Hangul and so on. Latin is used throughout the world for many languages in Western Europe, like English and Finnish, and for ones that were influenced by European colonization, like Vietnamese and Swahili. The Cyrillic alphabet is used in many countries in Eastern Europe, Central Asia, and North Asia. Some languages that use Cyrillic alphabets include Russian and Bulgarian. Whereas the Greek alphabet is used by modern Greek and its dialects, and by some minority languages in Greek-speaking majority areas, the Hangul alphabet, is used to write Korean.
An abjad, is a phonetic-based writing system in which the consonants get their own symbols, and vowels can be left unwritten. One important thing to keep in mind when creating UIs for languages that use these scripts is that these writing systems are almost entirely written right-to-left. Examples include many Semitic languages like Arabic and Hebrew.
A syllabary is a phonetic-based system of writing in which there is a different symbol for each possible syllable in a language. In contrast to the other phonetic-based systems, syllabaries are often invented, instead of being derived. Examples include Hiragana, which is one of the syllabaries used to write Japanese, and Katakana, used to write Ainu, an interesting language spoken in northern Japan and unrelated to Japanese. Then there is Tsalagi, the syllabary invented by Sequoyah for writing his native Cherokee language.
An abugida, sometimes known as alphasyllabary, neosyllabary or pseudo-alphabet, is a segmental writing system in which consonant-vowel sequences are written as a unit; each unit is based on a consonant letter, and vowel notation is secondary.Consider the most widely used abugida today, Devanagari. It originated some time before the 10th century AD, developed from the earlier Brahmi script. The other examples include, Thai, derived from the Brahmi script, and Ge’ez, used in East Africa to write various languages of Ethiopia.
Finally, we have writing systems where each grapheme can represent a whole word or morpheme of any length. They are called logographic writing systems. There is only one such system widely used today—Han Chinese characters. It is used to write most of the languages of China, as well as Japanese uses Hanji, Chinese logographs, combined with Hiragana.
Thanks for reading! I hope you found this article helpful. Read more data science articles here including tutorials from beginner to advanced levels!