Implementing Near Realtime Search with ElasticSearch

Introduction
A majority of companies believe that leveraging customer-data is the key to gaining competitive edge. In other words, the more customers you have, more data you are able to gather and analyze, which then allows you to build a better product. For this reason, leading companies invest heavily in database development and building other data infrastructure. More often than not, companies build their essential functionalities around relational databases. This is due to the fact that, relational databases have strict data integrity procedures that keep the integrity of crucial data throughout all database procedures and operations. However, traditional databases are ineffective for the purposes of analytics and implementing full-text search capabilities. Therefore, there is a need for a search engine that allows us to store, search, and analyze huge volumes of data quickly and in near real-time and give back answers in milliseconds.
A well established solution for this problem is to generate an index based on the data. An index can be built in different ways and one of the commonly used techniques is the inverted index. An inverted index is a database index storing a mapping from content, such as words or numbers to its location in a table, or in a document or in a set of documents. There are a lot of options available in terms of full text search engines. The snapshot below are some of the most popular ones as of June 2021. Some are open source, and others are commercial and licensed. The top 5 Open Source search engines include Elastic Search, Apache Solr, Lucene, Sphinx and Xapian. In this article, we will investigate one of the world’s leading solution, the ELK stack.

Elasticsearch is the world’s leading free and open search and analytics solution at the heart of the Elastic Stack that provides a rapid full-text search over millions of documents in near real-time. It is built on Apache Lucene and developed in Java. Logstash and Beats facilitate collecting, aggregating, and enriching your data and storing it in Elasticsearch. Kibana enables you to interactively explore, visualize, and share insights into your data and manage and monitor the stack. Elasticsearch is where the indexing, search, and analysis magic happens.
In order to take advantage of the robust search capabilities offered by Elasticsearch, many businesses will deploy Elasticsearch alongside existing relational databases. In this project, we explore the ELK stack and use Logstash to create a data pipe linking Elasticsearch to MySQL in order to build an index from scratch and keep Elasticsearch synchronized with MySQL database using Logstash and JDBC. The scenario is that, our legacy system uses MySQL database and we have a requirement where we need to have a heavy search and we have decided to move to Elasticsearch. We will still stick to our MySQL database as a primary database for application-db transactions and use ElasticSearch as a secondary data store for the requirements where we need to have the heavy search.
Dataset
The entire code files including the data file can be accessed in my github repository.
The submissions data set contains summary information about an entire EDGAR submission. Some fields were sourced directly from EDGAR submission information, while other columns of data were sourced from the Interactive Data attachments of the submission. Note: EDGAR derived fields represent the most recent EDGAR assignment as of a given filing’s submission date and do not necessarily represent the most current assignments. To access the complete submission files for a given filing, please see the SEC EDGAR website.
System Architecture
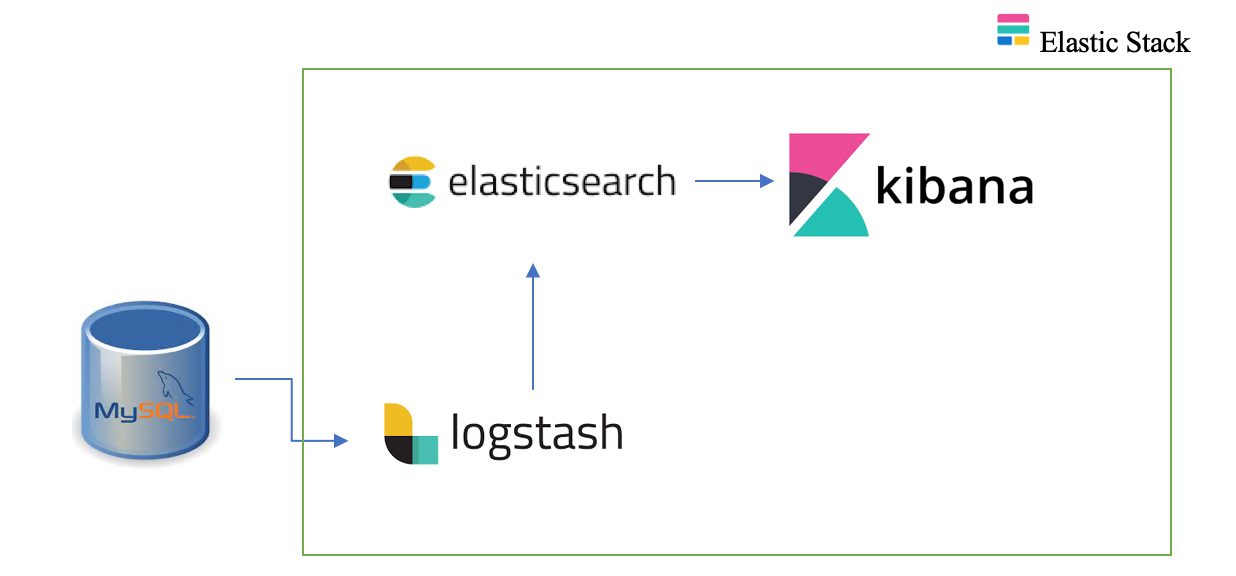
Before proceeding with the system architecture, let’s inspect the versions of various necessary elements such as the ELK stack, MySQL and the jdbc connector.
mysql:8
elasticsearch: 7.13.2
java version "1.8.0_291"
kibana:7.13.2
logstash:7.13.2
JDBC connector: Connector/J 8.0.25
Let’s now begin with a high-level overview of the system architecture to implement a proof of concept for data synchronization of MySQL database with Elasticsearch on Docker. A high-level system architecture is shown in the figure above. First and foremost, we shall configure the MySQL database. Since we are using Docker to implement this pipeline, we will begin by creating a directory for the project. The Docker Compose version used for this project is 3.3 and we shall examine each of the services in it. We shall create all the services and add them to a network. Since we do not have a database to work with, we shall build one from scratch. We will use the configuration mentioned below and start up the container.
version: '3.3'
services:
mysql:
image: mysql:8
container_name: cont_mysql
# restart: on-failure
ports:
- 3306:3306
expose:
- 3306
environment:
# MYSQL_RANDOM_ROOT_PASSWORD: "yes"
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: finstats
MYSQL_USER: es_user
MYSQL_PASSWORD: watchword
volumes:
# Dump files for initiating tables
- ./data/:/docker-entrypoint-initdb.d/
logging:
driver: "json-file"
options:
max-size: "10k"
max-file: "10"
networks:
- elastic
Next, we will fire up the terminal and navigate to the project directory. We will then run our Docker Compose file to bring up the containers. The commands at terminal are shown below.
docker-compose up -d
# Once container started, log into the MySQL container
docker exec -it cont_mysql bash
# Start a MySQL prompt
mysql -u es_user -p finstats
# Enter password used in MYSQL_PASSWORD in docker compose
# Check that tables have been loaded from dump files
use finstats;
show tables;
Then, we shall configure our database which we will use for synchronization with Elasticsearch. The code for database configuration is mentioned below.
CREATE DATABASE finstats;
USE finstats;
DROP TABLE IF EXISTS fin_sub;
CREATE TABLE fin_sub(
adsh VARCHAR(20) NOT NULL,
PRIMARY KEY (adsh),
UNIQUE KEY unique_id (adsh),
cik INT,
name VARCHAR(150),
sic INT,
countryba VARCHAR(2),
stprba VARCHAR(2),
cityba VARCHAR(30),
zipba VARCHAR(10),
bas1 VARCHAR(40),
bas2 VARCHAR(40),
baph VARCHAR(12),
countryma VARCHAR(2),
stprma VARCHAR(2),
cityma VARCHAR(30),
zipma VARCHAR(10),
mas1 VARCHAR(40),
mas2 VARCHAR(40),
countryinc VARCHAR(3),
stprinc VARCHAR(2),
ein VARCHAR(10),
former VARCHAR(150),
changed VARCHAR(8),
afs VARCHAR(5),
wksi TINYINT,
fye VARCHAR(4),
form VARCHAR(10),
period DATE,
fy YEAR(4),
fp VARCHAR(2),
filed DATE,
accepted DATETIME,
prevrpt TINYINT,
detail TINYINT,
instance VARCHAR(32),
nciks INT,
aciks VARCHAR(120),
modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);
Let’s discuss the most important parameters needed to understand the dataset.
fin_sub : This is the name of the MySQL table that records will be read from and then synchronized to Elasticsearch.
adsh: Accession Number is a 20-character string formed from the 18-digit number assigned by the SEC to each EDGAR submission and is a unique(primary) key for these records. Notice that “adsh” is defined as the PRIMARY KEY as well as a UNIQUE KEY. This guarantees each “adsh” only appears once in the current table. This will be translated to “_id” for updating or inserting the document into Elasticsearch.
modification_time: This field is used to track the insertion or updation of a record. It allows us to pull out any records that have been modified since the last time Logstash requested documents from MySQL.
insertion_time: This field is used to track when a record was originally inserted into MySQL(Only for demonstration purposes).
Then, we will load the data from the fin_sub.sql file in the /data/ folder within our project directory. We will download a mysql java connector which will be used by logstash to read the MySQL database. Moving forward, let’s put down the synchronization code that will be used by logstash to fetch data from our MySQL database.
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://mysql:3306/finstats"
jdbc_user => "es_user"
jdbc_password => "watchword"
tracking_column => "unix_ts_in_secs"
tracking_column_type => "numeric"
use_column_value => true
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM fin_sub WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
schedule => "*/5 * * * * *"
}
}
filter {
mutate {
copy => { "adsh" => "[@metadata][_id]"}
remove_field => ["adsh", "@version", "unix_ts_in_secs"]
}
}
output {
stdout { codec => "rubydebug"}
elasticsearch {
index => "finstats"
action => "index"
document_id => "%{[@metadata][_id]}"
hosts => ["http://es01:9200","http://es02:9200","http://es03:9200"]
}
}
We will then bring up the containers for our ELK stack. We will add the below code to the Docker Compose for the ELK stack.
version: '3.3'
services:
mysql:
...
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.13.2
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
- ./elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
ports:
- 9200:9200
logging:
driver: "json-file"
options:
max-size: "10k"
max-file: "10"
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.13.2
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
- ./elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.13.2
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
- ./elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
networks:
- elastic
kibana:
image: docker.elastic.co/kibana/kibana:7.13.2
container_name: cont_kib
ports:
- 5601:5601
environment:
ELASTICSEARCH_URL: "http://es01:9200"
ELASTICSEARCH_HOSTS: '["http://es01:9200","http://es02:9200","http://es03:9200"]'
depends_on:
- es01
- es02
- es03
networks:
- elastic
logstash:
image: docker.elastic.co/logstash/logstash:7.13.2
container_name: cont_logstash
# restart: on-failure
privileged: true
depends_on:
- mysql
- es01
- es02
- es03
volumes:
- ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml
- ./logstash/pipeline/logstash-sample.conf:/usr/share/logstash/pipeline/logstash.conf
- ./logstash/mysql-connector-java-8.0.25.jar:/usr/share/logstash/mysql-connector-java-8.0.25.jar
logging:
driver: "json-file"
options:
max-size: "10k"
max-file: "10"
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
external: true
Now that we have our docker-compose.yml file, we will fire up the terminal, and start it up!
docker-compose up -d
It might take some time for Kibana to start up. But, once Elasticsearch and Kibana are up and running, we can see a list of indices in the Elasticsearch nodes.
# Use the command docker exec -it <container name> /bin/bash to get a bash shell in the container.
docker exec -it es01 bash
# Check the indices in elasticsearch nodes within the Elasticsearch container
curl "es01:9200/_cat/indices?v=true&pretty"

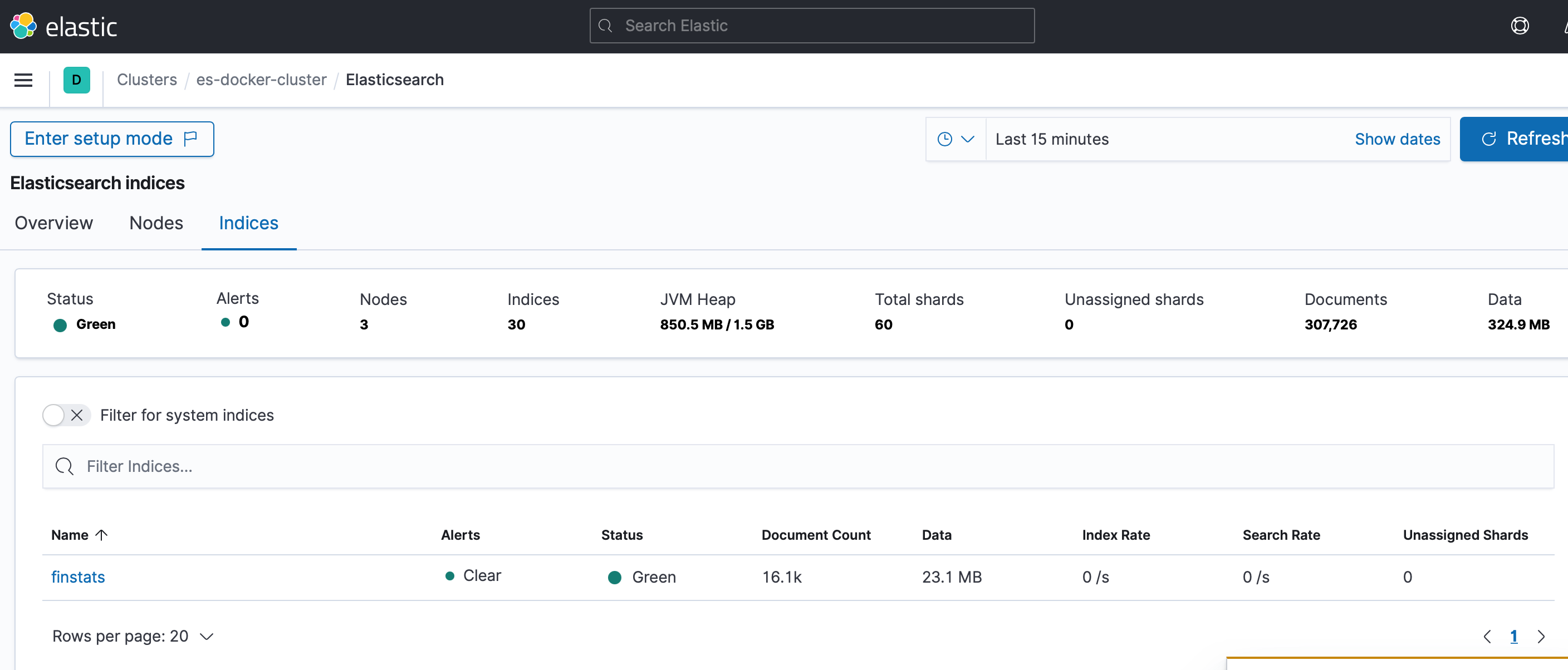
We can see our index finstats in the list and hence we can proceed to fire up the browser and start Kibana on the browser. We can navigate to Stack monitoring and find our indices as shown below.
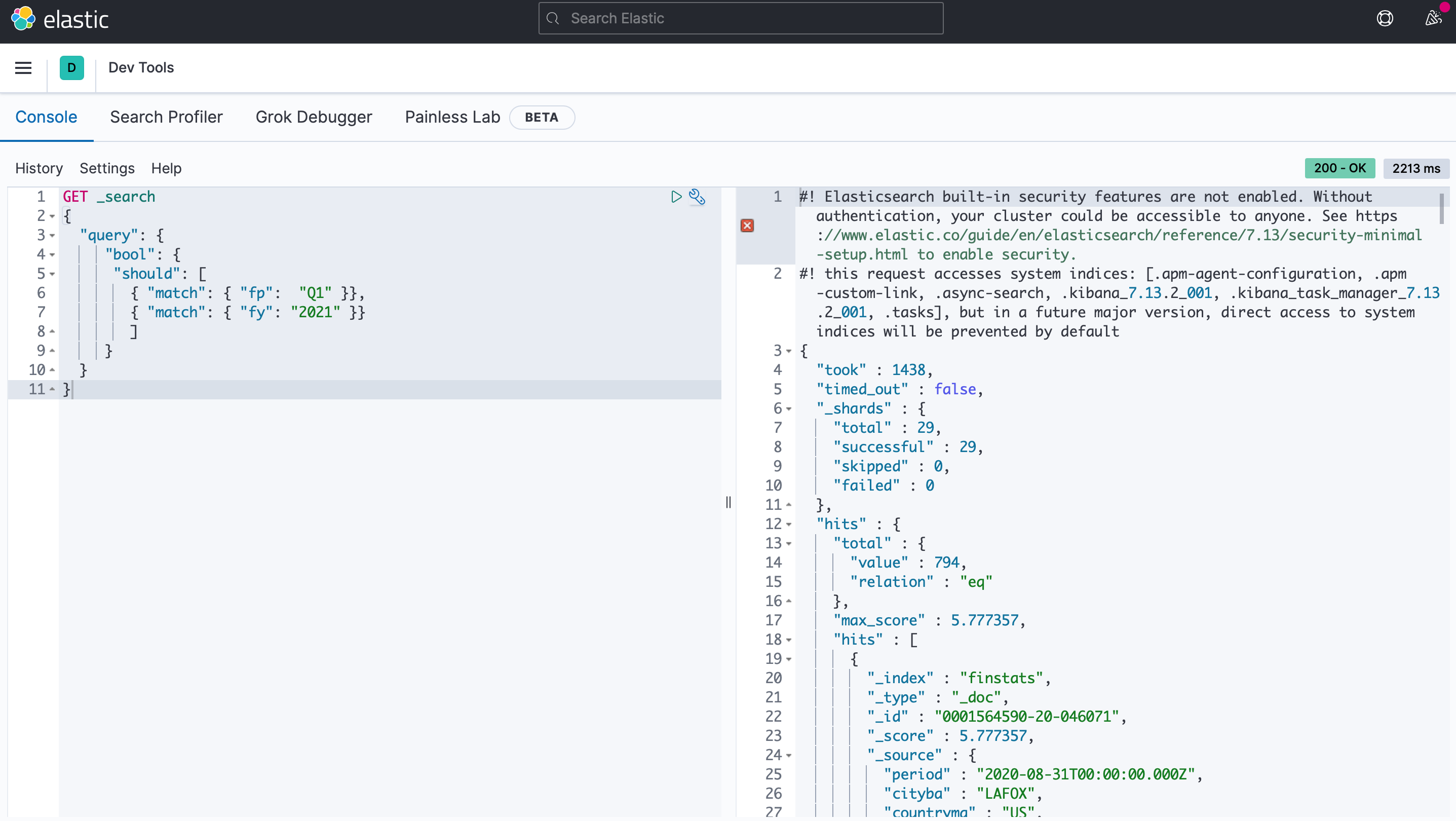
We shall then navigate to Dev Tools panel, where we can extract data from Elasticsearch. In the below example, we are searching for EDGAR filings for the first quarter of 2021. We see that it returns 794 documents.
Conclusion
In this article, I showed how Logstash can be used to synchronize Elasticsearch with a relational database. The code and methods presented here were tested with MySQL, but should theoretically work with any RDBMS.
Thanks for reading! If you want to get in touch with me or leave me any feedback, feel free to reach me on my email. You can find the complete script in my github repository.
References
(1) Elasticsearch. Elastic stack home page, 2021. https://www.elastic.co/products.
(2) Nigel Poulton. Docker Deep Dive. Packt Publishing. October 2020.
(3) Rich Collier, Camilla Montonen, Bahaaldine Azarmi. Machine Learning with the Elastic Stack - Second Edition. Packt Publishing.May 2021
(4) Doug Turnbull and John Berryman. Relevant Search: With applications for Solr and Elasticsearch. Manning Publications. June 2016
(5) Yuvraj Gupta, Ravi Kumar Gupta. Mastering Elastic Stack. Packt Publishing. February 2017
(6) Bharvi Dixit. Mastering Elasticsearch 5.x - Third Edition. Packt Publishing. February 2017.
(7) DB-Engines. Ranking of search engines, June 2021. https://db-engines.com/en/ranking/search+engine.