Extracting the hidden messages in Earnings Call Transcripts

Introduction
An earnings call is a conference call between the management of a public company, analysts, investors, and the media to discuss the company’s financial results during a given reporting period, such as a quarter or a fiscal year. Most listed US companies host earnings calls every quarter. There are hundreds of earnings calls held each quarter, often with the release of detailed transcripts. Earnings call transcripts delineate a compelling case for analysis because the transcript is relatively unstructured and potentially more informative than 10K and 10Q disclosures due to the question and answer session consisting of unprepared statements.
Although mining these unstructured public company transcripts gives us an informational edge on company strategy and expectations for future performance, the sheer volume of those transcripts makes analyzing them a daunting task. Although earnings call transcripts by themselves are not informative enough to predict stock price changes, they can be leveraged to gauge volatility or stability of underlying revenue stream. There are various machine learning techniques that can be used to extract the information from these transcripts. Some of them include Sentiment analysis, topic modeling, text summarization and so on.
Topic modeling is an area of natural language processing that analyses large volumes of text data and identifies the key topics or themes within the data. On the contrary, sentiment analysis, predicts sentiments about future outlooks by assigning sentiment scores on each topic of interest within the text and enables us to comprehend the sentiment conveyed by company management on earnings calls. Text summarization, enables us to automatically summarize single/ multiple documents to extract only the most relevant information.
Although companies often include summaries with earning releases, they might be prone to content management. Therefore, opting for automatic summarization is beneficial because it extracts text without human intervention and may provide useful summary information with less bias. In this work, we dive deeper into abstractive summarization technique to automatically summarize earnings call transcripts stored as a text file in a local path.
System Architecture
The original system architecture stored the web link to the earnings call transcripts in a MySQL database. To avoid sharing information related to credentials, this step was modified and the transcripts were downloaded and the text files were stored in local path. Subsequently, the filename was stored in the MYSQL database. The ETL(Extract, Transform and Load) pipeline for this project was implemented using a docker container with PySpark installed in Jupyter notebook and MySQL on the same network. The entire code files can be accessed in [my github repository](https://github.com/prabhupavitra/Text-Summarization-PySpark/blob/main/Abstractive%20Text%20Summarization%20using%20Pyspark.ipynb. Spark SQL also includes a data source that can read data from other databases using JDBC. Tables from the remote database can be loaded as a DataFrame or Spark SQL temporary view using the Data Sources API. Users can specify the JDBC connection properties in the data source options. user and password are normally provided as connection properties for logging into the data sources. The system architecture for this project is displayed below.
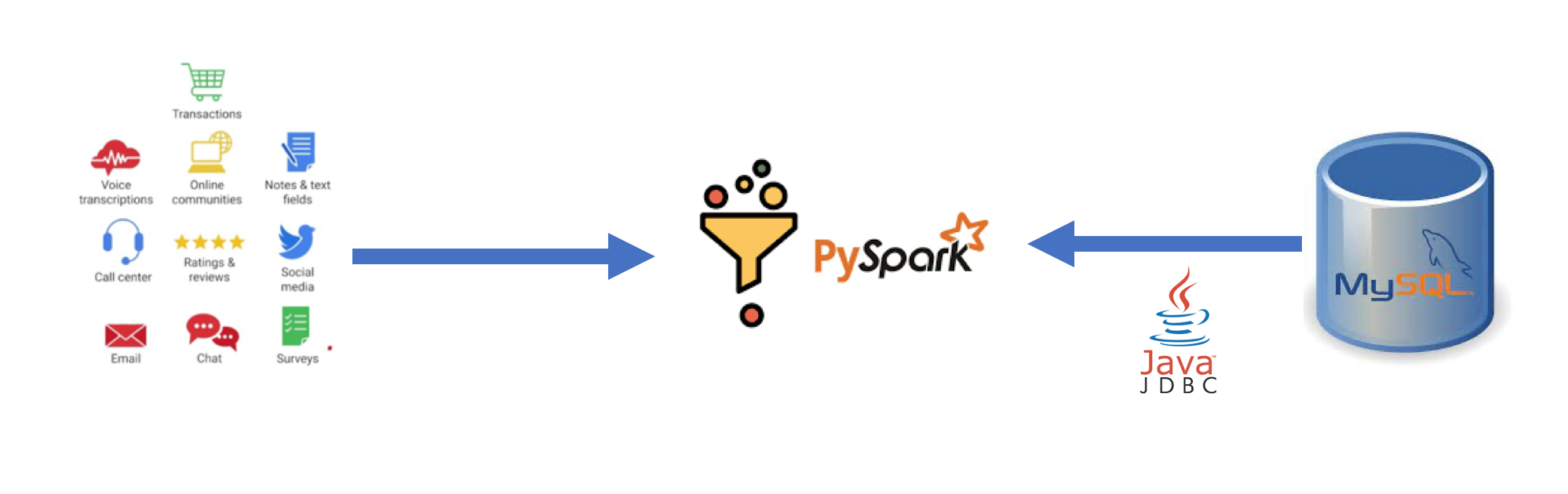
Data Acquisition
There are various ways to locate the transcripts. Some of the popular sources include Seeking Alpha, Factiva, Factset, Pitchbook, Capital IQ, Bloomberg and Westlaw Campus Research. Thomson One Streetevents is a great resource for earnings call transcripts and some limited audio recordings. Dow Jones Factiva also has earnings call transcripts, although they often include just a summary of the company’s presentation, along with the analysts’ questions, instead of including the word-for-word transcripts that are usually included with the Thomson Reuters Streetevents transcripts. Factset, available for use in Lippincott Library, also has earnings call transcripts and some audio broadcasts. However, the earnings call transcripts for this project were obtained from the website Seeking Alpha. The transcripts are well labeled, including the name of the speaker(executive and analysts) and speech content.
Methods & Analysis
Text Summarization
Text summarization is the process of shortening a set of data computationally, to create a subset (a summary) that represents the most important or relevant information within the original content. Automatic text summarization refers to the use of machine learning and natural language processing methods to address the ever-growing amount of text data available online to both better help discover relevant information and to consume relevant information faster.
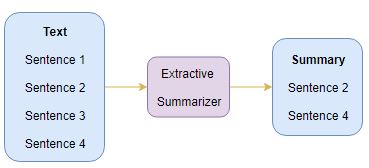
The algorithms designed for automatic text summarization can be partitioned into two main categories: Extractive Summarization and Abstractive Summarization. Extractive summarization approach aims at identifying the salient information that is then extracted and grouped together to form a concise summary.
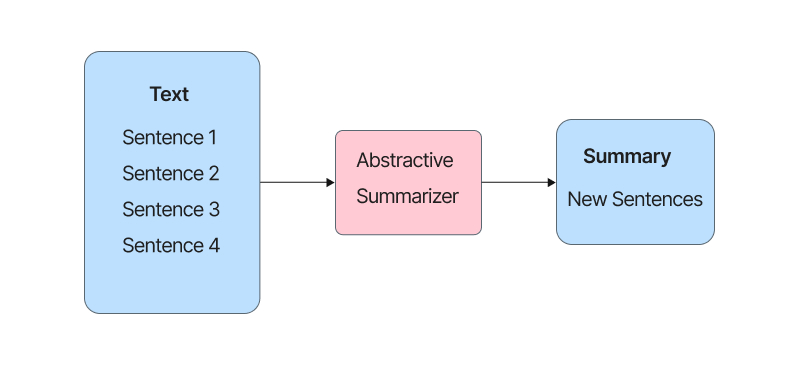
Abstractive summarization is so-called because they do not select sentences from the originally given text to create the summary, but generate entirely new phrases and sentences to capture the meaning of the source document. They offer the potential to generate human like summaries because of its ability to select words from a general vocabulary, rather than being limited to the input text like other automatic summarization methods.
Implementation
Diving into the implementation section, we begin loading the data from the mysql database to retrieve the filenames of all the firms whose earnings call transcripts needs to be summarized.To get started you will need to include the JDBC driver for your particular database on the spark classpath. For example, to connect to mysql from the Spark Shell you would use the following config when intiating a spark session.
.config("spark.driver.extraClassPath", "./mysql-connector-java-8.0.25.jar")
With regards to implementing the text summarization model, we leverage spark nlp library to implement abstractive summarization using T5 Transformer model. Spark NLP is a Natural Language Processing (NLP) library built on top of Apache Spark ML. It provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment. Spark NLP comes with 1100+ pretrained pipelines and models in more than 192+ languages. It supports nearly all the NLP tasks and modules that can be used seamlessly in a cluster.
On the other hand, T5: Text-to-Text-Transfer-Transformer model proposes reframing all NLP tasks into a unified text-to-text-format where the input and output are always text strings. This formatting makes one T5 model fit for multiple tasks with a uniform architecture. It was created by Google AI and the details can be found in this article.The complete seminar paper is available by clicking this link.
T5 is a transformer model trained on the “Colossal Clean Crawled Corpus” (C4) dataset. Google open-sourced a pre-trained T5 model that is capable of doing multiple tasks like translation, summarization, question answering, and classification. This T5-Small model has about 60 million parameters and using the smaller models can be helpful in settings where limited computational resources are available for fine-tuning or inference. In this project, we use T5-small pre-trained model to achieve abstractive text summarization of earnings call transcripts.
Moving forward, let’s dive into the execution of the project in detail. Spark ML provides a set of Machine Learning applications that can be build using two main components: Estimators and Transformers. The Estimators have a method called fit() which secures and trains a piece of data to such application. The Transformer is generally the result of a fitting process and applies changes to the the target dataset.
In Spark NLP, DocumentAssembler is a key transformer that serves as the entry point to Spark NLP for any spark dataframe. Another vital element of machine learning workflow in Spark NLP is a pipeline. Pipelines are a mechanism for combining multiple estimators and transformers in a single workflow. They allow multiple chained transformations along a Machine Learning task. For more information please refer to Spark ML library.
The complete code to achieve abstractive summarization is provided below:
# Install sparknlp
!pip install --upgrade sparknlp
import os
import sparknlp
from pyspark.sql.types import *
from pyspark.ml import Pipeline
# os.getcwd()
from pyspark.sql import SparkSession
# Initiating a Spark NLP Session
spark = SparkSession.builder \
.appName("Spark NLP")\
.master("local[4]")\
.config("spark.python.worker.memory","6G") \
.config("spark.driver.memory","24G")\
.config("spark.driver.maxResultSize", "0") \
.config("spark.kryoserializer.buffer.max", "2000M")\
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer") \
.config("spark.jars.packages", "com.johnsnowlabs.nlp:spark-nlp_2.12:3.1.1")\
.config("spark.driver.extraClassPath", "./mysql-connector-java-8.0.25.jar")\
.config("spark.worker.cleanup.enabled",True)\
.getOrCreate()
# // Loading data from a JDBC source
jdbcDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:mysql://sem_mysql:3306/test_db") \
.option("dbtable", "earningscall") \
.option("user", "es_user") \
.option("password", "watchword") \
.load()
from pyspark.sql.functions import concat,lit
folder_path = os.getcwd()
folder_name = "earnings_call_transcripts"
file_path = os.path.join(folder_path, folder_name, '')
jdbcDF = jdbcDF.select(concat(lit('file:'),lit(file_path),jdbcDF.filepath) \
.alias("local_filepath"),'companyid', 'ticker', 'company_name', 'filepath', 'transcript')
from pyspark.sql.types import *
from pyspark.sql.functions import *
# from pyspark.sql.functions import monotonically_increasing_id
file_path = "./earnings_call_transcripts/"
texts = spark.sparkContext.wholeTextFiles(file_path,use_unicode=True)
schema = StructType([
StructField('path', StringType()),
StructField('raw_text', StringType())
# StructField('text_len',IntegerType())
])
# Add index and Handle escape sequence of \x00 before tokenizing the document
textdf = spark.createDataFrame(texts, schema=schema).persist() \
.withColumn("index", monotonically_increasing_id()) \
.withColumn('text', regexp_replace('raw_text', '\x00|\n', ''))
# Add text length to the table
import pyspark.sql.functions as f
textdf = textdf.withColumn("original_text_length",f.length(col("text")))
# Join tables from mysql with pyspark table
jdbcJoinedTable = jdbcDF.join(textdf, jdbcDF.local_filepath == textdf.path, 'left').select(jdbcDF.local_filepath,jdbcDF.companyid,jdbcDF.ticker,jdbcDF.company_name,jdbcDF.filepath, textdf.text,textdf.original_text_length)
from sparknlp.annotator import *
from sparknlp.common import *
from sparknlp.base import *
from pyspark.ml import Pipeline
assembler = DocumentAssembler()\
.setInputCol('text')\
.setOutputCol('doc')
t5 = T5Transformer() \
.pretrained("t5_small") \
.setTask("summarize:")\
.setMaxOutputLength(500)\
.setInputCols(["doc"]) \
.setOutputCol("summaries")
pipeline = Pipeline().setStages([assembler, t5])
results = pipeline.fit(jdbcJoinedTable).transform(jdbcJoinedTable)
# results.printSchema()
# Summary of Earnings call Transcripts for Broadcom Q
results.filter(col("ticker") == "AMAT").select(['summaries.result']).toPandas()['result'][0][0]
The corresponding summary of the ticker mentioned above is as follows:
'Applied Materials, Inc. is a company that has a diversified
portfolio of products . a lot of people are embracing the
technology, and the technology is a key driver . a lot of
people are embracing the technology, and the technology
is a key driver .'
Conclusion
Overall, there are some interesting takeaways from this NLP analysis of earnings calls, although they should be combined with other metrics to form a more holistic viewpoint on industry trends.
Thanks for reading! If you want to get in touch with me or leave me any feedback, feel free to reach me on my email. You can find the complete script in my github repository.
References
(1) Sowmya Vajjala, Bodhisattwa Majumder, Anuj Gupta, Harshit Surana. Practical Natural Language Processing. O’Reilly Media, Inc. June 2020.
(2) Alex Thomas. Natural Language Processing with Spark NLP.O’Reilly Media, Inc.June 2020.
(3) Jeffrey Aven. Data Analytics with Spark Using Python, First edition.O’Reilly Media, Inc.June 2018
(4) Josh Wills, Sean Owen, Sandy Ryza and Uri Laserson.Advanced Analytics with Spark, 2nd Edition. O’Reilly Media, Inc.June 2017
(5) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu.Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer .June 2020. https://arxiv.org/pdf/1910.10683.pdf